
建表并插入数据
## 建表
create table if not exists student(
s_id int(11) not null auto_increment comment '学号',
s_name varchar(5) not null comment '姓名',
s_age int(3) not null comment '年龄',
s_sex int(1) not null comment '性别',
primary key (s_id)
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 comment '学生表';
插入数据
#添加多行数据
insert into student(s_id, s_name, s_age, s_sex) values
(default,'小兰',18,1),(default,'小白',20,0),(default,'小黑',25,0),(default,'小花',22,1),
(default,'张三',23,0),(default,'李四',20,0),(default,'翠花',19,1),(default,'大海',18,0);
跑
maven方式引入jar
<dependency>
<group
注解
@Data
public class Student {
private Integer sId;
private String sName;
private Integer sAge;
private int sSex;
}
mybatis-config.xml基础配置
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<!-- 开启驼峰 -->
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
<!-- 配置环境 environments = 可以有多个环境 我们只配置一个-->
<environments default="development">
<!-- 配置 -->
<environment id="development">
<!--事务默认使用JDBC-->
<transactionManager type="JDBC"/>
<!-- 数据源 -->
<dataSource type="POOLED">
<!-- 数据库驱动 -->
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<!-- 数据库url -->
<property name="url" value="jdbc:mysql://localhost:3306/gold?characterEncoding=utf8&useSSL=false&allowPublicKeyRetrieval=true"/>
<!-- 数据库用户名 -->
<property name="username" value="root"/>
<!-- 密码 -->
<property name="password" value="123456"/>
</dataSource>
</environment>
</environments>
<!-- mapper.xml的具体位置 -->
<mappers>
<mapper resource="mapper/StudentMapper.xml"/>
</mappers>
</configuration>
mapper接口
public interface StudentMapper {
//查询全部
public List<Student> allStudent();
}
mapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- 那个接口的mapper.xml -->
<mapper namespace="com.qc.mapper.StudentMapper">
<!-- id:接口方法名称一样 resultType:数据库查询返回加过的类型 下面是sql语句 -->
<select id="allStudent" resultType="com.qc.entity.Student">

SqlSession sqlSession = sqlSessionFactory.openSession();
//通过SqlSession.getMapper 传入mapper.class 拿到mapper对象
StudentMapper mapper = sqlSession.getMapper(StudentMapper.class);
//运行方法,获得数据
List<Student> students = mapper.allStudent();
//遍历
students.forEach(System.out::println);
} catch (IOException e) {
e.printStackTrace();
}
}
结果

配置
configuration(配置):
properties(属性)
settings(设置)
typeAliases(类型别名)
typeHan

ectFac
ugins(插件)
environments(环境配置)
* environment(环境变量)
* transactionManager(事务管理器)
* dataSource(数据源)
databaseIdProvider(数据库厂商标识)
mappers(映射器)
属性(properties)
在resources中创建jdbc.properties
driver=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/gold?characterEncoding=utf8&useSSL=false&allowPublicKeyRetrieval=true
username=root
password=123456
这些属性可以在外部进行配置,并可以进行动态替换
在mybatis-config.xml中引入配置
<properties resource="jdbc.properties"/>

配置必须按照指定优先顺序来,不然就会报错(顺序看最上面 -->configuration(配置))
设置好的属性可以在整个配置文件中用来替换需要动态配置的属性值。比如:
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
设置(settings)
这是 MyBatis 中极为重要的调整设置,它们会改变 MyBatis 的运行时行为。 下表描述了设置中各项设置的含义、默认值等。
一个配置完整的 settings 元素的示例如下:
<settings>
<setting name="cacheEnabled" value="true"/>
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="multipleResultSetsEnabled" value="true"/>
<setting name="useColumnLabel" value="true"/>
<setting name="useGeneratedKeys" value="false"/>
<setting name="autoMappingBehavior" value="PARTIAL"/>
<setting name="autoMappingUnknownColumnBehavior" value="WARNING"/>
<setting name="defaultExecutorType" value="SIMPLE"/>
<setting name="defaultStatementTimeout" value="25"/>
<setting name="defaultFetchSize" value="100"/>
<setting name="safeRowBoundsEnabled" value="false"/>
<setting name="mapUnderscoreToCamelCase" value="false"/>
<setting name="localCacheScope" value="SESSION"/>
<setting name="jdbcTypeForNull" value="OTHER"/>
<setting name="lazyLoadTriggerMethods" value="equals,clone,hashCode,toString"/>
</settings>
类型别名(typeAliases)
类型别名可为 Java 类型设置一个缩写名字。 它仅用于 XML 配置,意在降低冗余的全限定类名书写。
就是为我们的java类设置一个简写的名称,以后在其他地方都可以使用简写名称。
比如:
<typeAliases>
<typeAlias alias="Student" type="com.qc.entity.Student"/>
</typeAliases>
在mapper.xml中就可以直接写Student
<select id="allStudent" resultType="Student">
select * from student;
</select>
也可以指定一个包名,MyBatis 会在包名下面搜索需要的 Java Bean
没有使用注解指定名称的话,默认会使用 Bean 的首字母小写的非限定类名来作为它的别名
<typeAliases>
<package name="com.qc"/>
</typeAliases>
也可以使用@Alias("name")注解来指定
@Alias("student")
public class Student{
...
}
常用别名映射
环境配置(environments)
MyBatis 可以配置成适应多种环境,这种机制有助于将 SQL 映射应用于多种数据库之中, 现实情况下有多种理由需要这么做。例如,开发、测试和生产环境需要有不同的配置;或者想在具有相同 Schema 的多个生产数据库中使用相同的 SQL 映射。还有许多类似的使用场景。
不过要记住:尽管可以配置多个环境,但每个 SqlSessionF

onFactory 实例,每个数据库对应一个。而如果是三个数据库,就需要三个实例,依此类推,记起来很简单: 每个数据库对应一个 SqlSessionFactory 实例
environments 元素定义了如何配置环境。
<environments default="development">
<environment id="development">
<transactionManager type="JDBC">
</transactionManager>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
注意一些关键点:
默认使用的环境 ID(比如:default="development")。
每个 environment 元素定义的环境 ID(比如:id="development")。
事务管理器的配置(比如:type="JDBC")。
数据源的配置(比如:type="POOLED")。
事务管理器(transactionManager)
在 MyBatis 中有两种类型的事务管理器(也就是 type="[JDBC|MANAGED]"):
JDBC – 这个配置直接使用了 JDBC 的提交和回滚设施,它依赖从数据源获得的连接来管理事务作用域。
MANAGED – 这个配置几乎没做什么。它从不提交或回滚一个连接,而是让容器来管理事务的整个生命周期(比如 JEE 应用服务器的上下文)。 默认情况下它会关闭连接。然而一些容器并不希望连接被关闭,因此需要将 closeConnection 属性设置为 false 来阻止默认的关闭行为。例如:
<transactionManager type="MANAGED">
<property name="closeConnection" value="false"/>
</transactionManager>
如果你正在使用 Spring + MyBatis,则没有必要配置事务管理器,因为 Spring 模块会使用自带的管理器来覆盖前面的配置。
数据源(dataSource)
有三种内建的数据源类型
UNPOOLED
POOLED
JNDI
默认使用POOLED就好
POOLED– 这种数据源的实现利用“池”的概念将 JDBC 连接对象组织起来,避免了创建新的连接实例时所必需的初始化和认证时间。 这种处理方式很流行,能使并发 Web 应用快速响应请求。
映射器(mappers)
使用相对于类路径的资源引用
推荐使用
<
使用完全限定资源定位符(URL)
<mappers>
<mapper url="file:///var/mappers/AuthorMapper.xml"/>
<mapper url="file:///var/mappers/BlogMapper.xml"/>
<mapper url="file:///var/mappers/PostMapper.xml"/>
</mappers>
使用映射器接口实现类的完全限定类名
<mappers>
<mapper class="org.mybatis.builder.AuthorMapper"/>
<mapper class="org.mybatis.builder.BlogMapper"/>
<mapper class="org.mybatis.builder.PostMapper"/>
</mappers>
注意:
接口和mapper必须同名
接口和mapper配置文件必须在同一个包下
将包内的映射器接口实现全部注册为映射器
<mappers>
<package name="org.mybatis.builder"/>
</mappers>
注意:
接口和mapper必须同名
接口和mapper配置文件必须在同一个包下
其他配置
typeHandlers(类型处理器) objectFactory(对象工厂) plugins(插件)
都很少用到,不重要,随便了解哈就行了。
作用域(Scope)和生命周期
生命周期,和作用域,是至关重要的,因为错误的使用会导致非常严重的并发问题
SqlSessionFactoryBuilder
这个类可以被实例化、使用和丢弃,一旦创建了 SqlSessionFactory,就不再需要它了。 因此 SqlSessionFactoryBuilder 实例的最佳作用域是方法作用域(也就是局部方法变量)。 你可以重用 SqlSessionFactoryBuilder 来创建多个 SqlSessionFactory 实例,但最好还是不要一直保留着它,以保证所有的 XML 解

actory
SqlSessionFactory 一旦被创建就应该在应用的运行期间一直存在,没有任何理由丢弃它或重新创建另一个实例。 使用 SqlSessionFactory 的最佳实践是在应用运行期间不要重复创建多次,多次重建 SqlSessionFactory 被视为一种代码“坏习惯”。因此 SqlSessionFactory 的最佳作用域是应用作用域。 有很多方法可以做到,最简单的就是使用单例模式或者静态单例模式。
SqlSession
每个线程都有一个SqlSession 实例,SqlSession 实例是不被共享的,并且不是线程安全的。因此最好的作用域是request 或者方法体作用域。不要用一个静态字段或者一个类的实例字段来保存SqlSession 实例引用。也不要用任何一个管理作用域,如Servlet 框架中的HttpSession,来保存SqlSession 的引用。如果正在用一个WEB 框架,可以把SqlSession 的作用域看作类似于HTTP 的请求范围。也就是说,在收到一个HTTP 请求,我们可以打开一个SqlSession,当您把response 返回时,就可以把SqlSession 关闭。关闭会话是非常重要的,应该要确保会话在一个finally 块中被关闭。
ResultMap
结果集映射
resultMap 元素是 MyBatis 中最重要最强大的元素。它可以让你从 90% 的 JDBC ResultSets 数据提取代码中解放出来,并在一些情形下允许你进行一些 JDBC 不支持的操作。
constructor:用于在实例化类时,注入结果到构造方法中
idArg:ID 参数;标记出作为 ID 的结果可以帮助提高整体性能
arg:将被注入到构造方法的一个普通结果
id:一个 ID 结果;标记出作为 ID 的结果可以帮助提高整体性能
result:注入到字段或 JavaBean 属性的普通结果
association:一个复杂类型的关联;许多结果将包装成这种类型
嵌套结果映射 – 关联可以是 resultMap 元素,或是对其它结果映射的引用
collection – 一个复杂类型的集合
嵌套结果映射 – 集合可以是 resultMap 元素,或是对其它结果映射的引用
discriminator:使用结果值来决定使用哪个 resultMap
case – 基于某些值的结果映射
嵌套结果映射 – case 也是一个结果映射,因此具有相同的结构和元素;或者引用其它的结果映射
案例
@Data
public class Stud
m.qc.mapper.StudentMapper">
<resultMap id="test" type="student">
<!-- column 数据库中的字段 property 实体类中的属性 -->
<result column="s_id" property="sId"/>
<result column="s_name" property="sName"/>
<result column="s_age" property="sAge"/>
<!-- 数据库字段和实体类不一样,可以进行映射 -->
<result column="s_sex" property="sex"/>
</resultMap>
<!-- 返回类型为上面定义的resultMap id -->
<select id="allStudent" resultMap="test">
select * from student;
</select>
</mapper>
你完全可以不用显式地配置它们
只配置不一样的字段
<mapper namespace="com.qc.mapper.StudentMapper">
<resultMap id="test" type="student">
<!-- 只配置不一样的字段 -->
<result column="s_sex" property="sex"/>
</resultMap>
<!-- 返回类型为上面定义的resultMap id -->
<select id="allStudent" resultMap="test">
select * from student;
</select>
</mapper>
日志
日志工厂
出现错误、异常,我们需要拍错,依靠的就是日志

常见日志:
SLF4J
LOG4J
LOG4J2
JDK_LOGGING
COMMONS_LOGGING
STDOUT_LOGGING
NO_LOGGING
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
</settings>
注意:
name必须一样
value不能更改和有空格
如果需要使用其它的日志需要导包和配置日志文件
分页查询
逻辑分页——RowBounds
通过RowBounds类可以实现Mybatis逻辑分页,原理是首先将所有结果查询出来,然后通过计算offset和limit,只返回部分结果,操作在内存中进行,所以也叫内存分页。弊端很明显,当数据量比较大的时候,肯定是不行的,所以一般不会去使用RowBounds进行分页查询,这里仅提一下(懒!)。Mybatis Generator原生支持RowBounds查询,生成的Mapper接口中存在一个方法selectByExampleWithRowbounds就是通过RowBounds进行分页查询。
不推荐
使用limit物理分页
接口

mapper

test方法
mybatis注解
注解列表:
@Select:查询sql
@Insert:插入sql
@Update:更新sql
@Delete:删除sql
@Param:入参
@Results:设置结果集合@Result : 结果
@ResultMap:引用结果集合
@SelectKey:获取最新插入id
@Select
//分页查询
@Select("select * from student limit #{pageNum},#{pageSize}")
public List<Student> limitStudent(Map<String, Integer> map);
###
//增加
@Insert("insert into student values(default,#{SName},#{sAge},#{sex})")
public void addStudent(Student student);
@Update
//更新、修改
@Update("update student set s_name = #{sName} where s_id = #{sI
public void deleteStudentById(Integer sId);
复杂查询
建库建表
创建数据库
#创建数据库
create database if not exists mybatis default charset utf8mb4 collate utf8mb4_general_ci;
建表
老师表
# 老师表
create table if not exists teacher(
id int(11) not null auto_increment comment '老师id',
name varchar(5) default null comment '老师名称',
primary key (id)
)engine = InnoDB default charset =utf8mb4 comment '老师表';
学生表
#学生表
create table if not exists student(
id int(11) not null auto_increment comment '学生id',
name varchar(5) default null comment '学生姓名',
t_id int(11) default null comment '学生老师id',
primary key (id),
key fktid (t_id),
constraint fktid foreign key (t_id) references teacher (id)
)engine = InnoDB default charset = utf8mb4 comment '学生表';
插入数据
#老师表插入数据
insert into teacher(id,name) value(default,'王老师');
#学生表插入数据
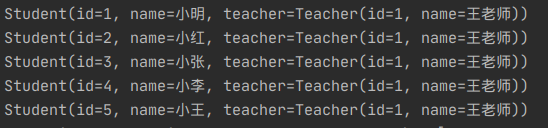
insert into student(id, name, t_id) VALUES
(default,'小明',1),(default,'小红',1),(default,'小张',1),
(default,'小李',1),(default,'小王',1)
多对一
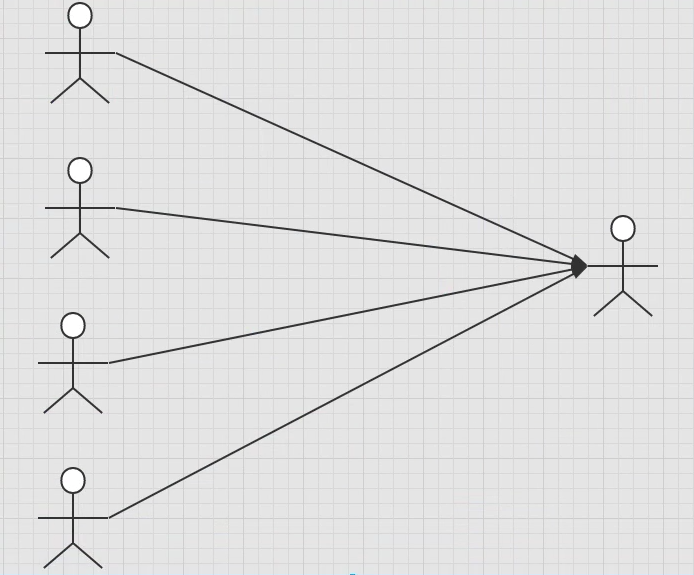
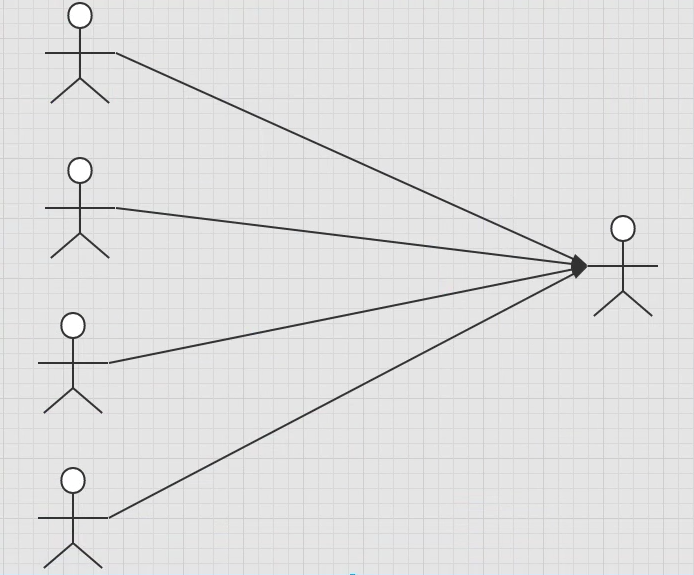
对于学生而言,多个学生对应一个老师
对于老师而言,一个老师对应多个学生
代码
pojo
@Data
public class Teacher {
private Integer id;
private String name;
}
@Data
public class Student {
private Integer id;
private String name;
//学生对应的老师
private Teacher teacher;
}
Mapper
public interface StudentMapper {
//查询所有学生信息和其老师
public List<Student> allStudentTeacher();
}
Mapper.xml
<mapper namespace="com.qc.mapper.StudentMapper">
<resultMap id="stmap" type="student">
<result property="id" column="id"/>
<result property="name" column="sname"/>
<!-- 实体类是本累的teacher属性 对应的是一个java类型 -->
<association property="teacher" javaType="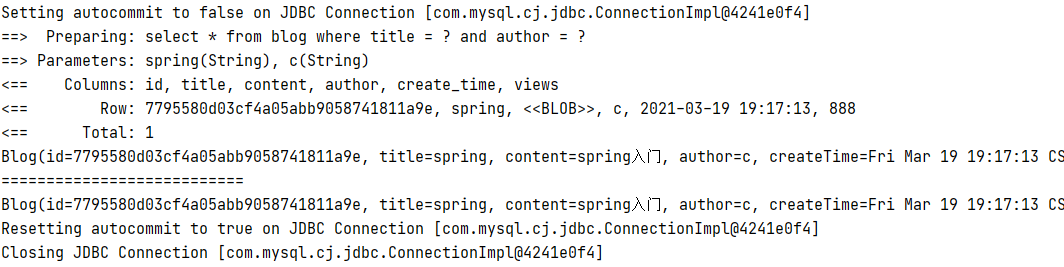
Teacher();
studentList.forEach(System.out::println);
sqlSession.close();
} catch (IOException e) {
e.printStackTrace();
}
}
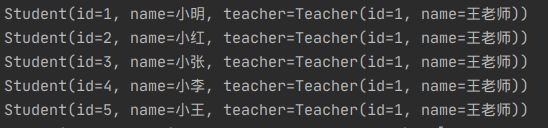
一对多
pojo
@Data
@Alias("teacher")
public class Teacher {
private Integer id;
private String name;
//一个老师有多个学生
private List<Student> studentList;
}
@Data
@Alias("student")
public class Student {
private Integer id;
private String name;
private Integer tId;
}
mapper
public interface TeacherMapper {
public Teacher allTeacher();
}
mapper.xml
<mapper namespace="com.qc.mapper.TeacherMapper">
<!-- 一对多:查询老师的信息,包括老师的学生 -->
<select id="allTeacher" resultMap="tsMap">
select t.id t_id,t.name t_name,
s.id s_id,s.name s_name,s.t_id s_tid
from teacher t right join student s on t.id = s.t_id
</select>
<resultMap id="tsMap" type="teacher">
<result property="id" column="t_id"/>
<result property="name" column="t_name"/>
<!-- 实体类是一个学生的集合 所以使用collection代表集合 ofType代表集合泛型 -->
<collection property="studentList" ofType="Student">
<result property="id" column="s_id"/>
<result property="name" column="s_name"/>
<result property="tId" column="s_tid"/>
</collection>
</resultMap>
</mapper>
test
public class TeacherMapperTest {
@Test
public void allTeacher(){
SqlSession sqlsession = MybatisUtil.getSqlsession();
TeacherMapper mapper = sqlsession.getMapper(TeacherMapper.class);
Teacher teacher = mapper.allTeacher();
System.out.println(teacher);
sqlsession.close();
}
l comment '标题',
content longtext comment '内容',
author varchar(30) not null comment '作者',
create_time datetime not null comment '时间',
views int(11) not null comment '浏览量'
)engine = InnoDB default charset=utf8mb4 comment '博客表';
插入数据
insert into blog(id, title, content, author, create_time, views) values
('582f2f31a560406e9b218b77166d84e8','mybatis','mybatis入门','c',now(),999),
('7795580d03cf4a05abb9058741811a9e','spring','spring入门','c',now(),888),
('88c1b967b8b54d74bee19d964f8975dc','springboot','springboot入门','cz',now(),777),
('26179bfe6a2449c38db6edf616876a3d','mysql','mysql入门','cz',now(),666),
('63fd9e7d658c48daabc43fc75ebd3d54','java','java入门','x',now(),222),
('28cbd309d6ed4fc7bd3bc274377f9f2','golang','golang入门','x',now(),99);
pojo
@Data
@Alias("blog")
public class Blog {
private String id;
private String title;
private String content;
private String author;
private Date createTime;
private Integer views;
}
动态sql就是指根据不同的条件生成不同的sql语句
if
choose (when, otherwise)
trim (where, set)
foreach
if
<mapper namespace="com.qc.mapper.BlogMapper">
<select id="likeBlog" parameterType="map" resultType="blog">
<!-- where 1=1 不影响查询,只是为了加上where,方便后面if动态查询 -->
select * from blog where 1=1
<!-- 如果传入的map里面没有数据,下面不执行,如果里面有title,或者author,则添加如下sql -->
<if test="title != null">
and title = #{title}
</if>
<if test="author != null">
and author = #{author}
</if>
</select>
</mapper>
Test
@Test
public void likeBlog(){
SqlSession sqlsession = MybatisUtil.getSqlsession();
BlogMapper mapper = sqlsession.getMapper(BlogMapper.class);
Map<String, String> map = new HashMap<>();
map.put("author","c");
List<Blog> blogs = mapper.likeBlog(map);
blogs.forEach(System.out::println);
sqlsession.close();
}

choose、when、otherwise
不想使用所有的条件,而只是想从多个条件中选择一个使用,。针对这种情况,MyBatis 提供了 choose 元素,它有点像 Java 中的 switch 语句
<select id="likeBlog2" parameterType="map" resultType="blog">
select * from blog where 1=1
<choose>
<!-- 如果title有数据就只添加这个条件 -->
<when test="title != null">
and title = #{title}
</when>
<!-- 如果只有author 就会添加这个条件 -->
<when test="author != null">
and author = #{author}
</when>
<!-- 没有数据则默认添加这个条件 -->
<otherwise>
and views > 666
</otherwise>
</choose>
</select>
trim、where、set
where
上面where1=1是不正规的,所有mybatis添加了where元素。
where 元素只会在子元素返回任何内容的情况下才插入 “WHERE” 子句。而且,若子句的开头为 “AND” 或 “OR”,where 元素也会将它们去除。
<select id="likeBlog2" parameterType="map" resultType="blog">
<!-- where 1=1 不影响查询,只是为了加上where,方便后面if动态查询 -->
select * from blog
<where>
<choose>
<!-- 如果title有数据就只添加这个条件 -->
<when test="title != null">
title = #{title}
</when>
<!-- 如果只有author 就会添加这个条件 -->
<when test="author != null">
author = #{author}
</when>
<!-- 没有数据则默认添加这个条件 -->
<otherwise>
and views > 666
</otherwise>
</choose>
</where>
</select>
效果:

简单说就是如果有匹配条件的sql就会自动加上where,如果匹配的条件多了不需要的and,也会自动剔除。
trim
如果 where 元素与你期望的不太一样,你也可以通过自定义 trim 元素来定制 where 元素的功能。比如,和 where 元素等价的自定义 trim 元素为(感觉相当于对where元素的扩展):
<trim prefix="WHERE" prefixOverrides="AND |OR ">
...
</trim>
prefixOverrides 属性会忽略通过管道符分隔的文本序列(注意此例中的空格是必要的)。上述例子会移除所有 prefixOverrides 属性中指定的内容,并且插入 prefix 属性中指定的内容。
<select id="likeBlog" parameterType="map" resultType="blog">
<!-- where 1=1 不影响查询,只是为了加上where,方便后面if动态查询 -->
select * from blog
<trim prefix="where" prefixOverrides="AND |OR ">
<!-- 如果传入的map里面没有数据,下面不执行,如果里面有title,或者author,则添加如下sql -->
<if test="title != null">
and title = #{title}
</if>
<if test="author != null">
and author = #{author}
</if>
</trim>
</select>

set
简单理解就是用来更新数据时用到,判断是否传入了要更新字段的数据,没有传入就不更新改字段,传入了就更新。
用于动态更新语句的类似解决方案叫做 set。set 元素可以用于动态包含需要更新的列,忽略其它不更新的列。比如:
<update id="updateBlog" parameterType="blog">
update blog
<set>
<!-- 如果传入了那个字段字,判断有就更新该数据 别忘了后面要加逗号-->
<if test="title !=null">title = #{title},</if>
<if test="content !=null">content = #{content},</if>
<if test="author !=null">author = #{author},</if>
<if test="createTime !=null">create_time = #{createTime},</if>
<if test="views !=null">views = #{views}</if>
</set>
where id = #{id}
</update>
@Test
public void updateBlog(){
SqlSession sqlsession = MybatisUtil.getSqlsession();
BlogMapper mapper = sqlsession.getMapper(BlogMapper.class);
//创建blog对象传入要修改的信息
Blog blog = new Blog();
blog.setId("88c1b967b8b54d74bee19d964f8975dc");
blog.setTitle("修改后的springboot");
blog.setContent("修改后不入门了,直接入土。");
blog.setCreateTime(new Date());
mapper.updateBlog(blog);
sqlsession.commit();
sqlsession.close();
}

从sql可以看出,mybatis添加了我们给了数据的字段。

数据库数据也修改成功。
set 元素等价的自定义 trim 元素
<!-- suffixOverrides后缀覆盖:因为加了逗号,如果只有第一句匹配了,但是sql语句就多了个逗号,因此需要去除
(就是为了去除多余的逗号) -->
<trim prefix="SET" suffixOverrides=",">
...
</trim>
update blog
<trim prefix="set" suffixOverrides=",">
<!-- 如果传入了那个字段字,判断有就更新该数据 -->
<if test="title !=null">title = #{title},</if>
<if test="content !=null">content = #{content},</if>
<if test="author !=null">author = #{author},</if>
<if test="createTime !=null">create_time = #{createTime},</if>
<if test="views !=null">views = #{views}</if>
</trim>
where id = #{id}
</update>
Mapper元素--sql
sql元素就是将动态sql封装一下,提高复用性
<!-- 将动态sql的if语句全部抽出来 -->
<sql id="if-title-author">
<if test="title != null">
and title = #{title}
</if>
<if test="author != null">
and author = #{author}
</if>
</sql>
<select id="likeBlog" parameterType="map" resultType="blog">
<!-- where 1=1 不影响查询,只是为了加上where,方便后面if动态查询 -->
select * from blog
<trim prefix="where" prefixOverrides="and">
<!-- 使用include使用抽出来的动态sql -->
<include refid="if-title-author"></include>
</trim>
</select>
注意事项:
最好用于单表
不要把where放sql里
foreach
动态 SQL 的另一个常见使用场景是对集合进行遍历(尤其是在构建 IN 条件语句的时候)
<select id="queryBlog" parameterType="arraylist" resultType="blog">
<!-- 正常的sql是:
select * from blog where id in ('582f2f31a560406e9b218b77166d84e8','7795580d03cf4a05abb9058741811a9e');
但是为了动态的查询,我们将要查询的多个id放入Arraylist中
在sql中要把集合中的数据取出来,并包装成 in (id,id,id) 的形式
item:集合中每个数据对应的字段 collection:存入集合的引用
open:开始用啥拼接 separator:用什么做分割 close:结束用啥拼接
-->
select * from blog
<where>
id in
<foreach item="id" collection="list" open="(" separator="," close=")">
#{id}
</foreach>
</where>
</select>
结果:

script
要在带注解的映射器接口类中使用动态 SQL,可以使用 script 元素:
(又是大括号,又引号,还有逗号,脑瘫才有!!!!!!!^-^)
@Update({
"<script>",
"update blog",
" <set>",
" <if test='title != null'>title=#{title},</if>",
" <if test='content != null'>content=#{content},</if>",
" <if test='author != null'>author=#{author},</if>",
" <if test='createTime != null'>create_time=#{createTime},</if>",
" <if test='views != null'>views=#{views},</if>",
" </set>",
"where id=#{id}",
"</script>"
})
public void updateBlog(Blog blog);
缓存
科普: 什么是缓存?
存在内存中的临时数据
将用户经常访问的数据存在缓存(内存)中,用户去查询数据就不用从磁盘查询,而是从缓存中查询,提高查询效率,解决了高并发系统的性能问题
为什么使用缓存?
减少和数据库交互的次数,减少系统开销,提高效率,减小数据库压力。
什么样的数据适合缓存?
经常查询且长时间不改变的数据
MyBatis 内置了一个强大的事务性查询缓存机制,它可以非常方便地配置和定制。
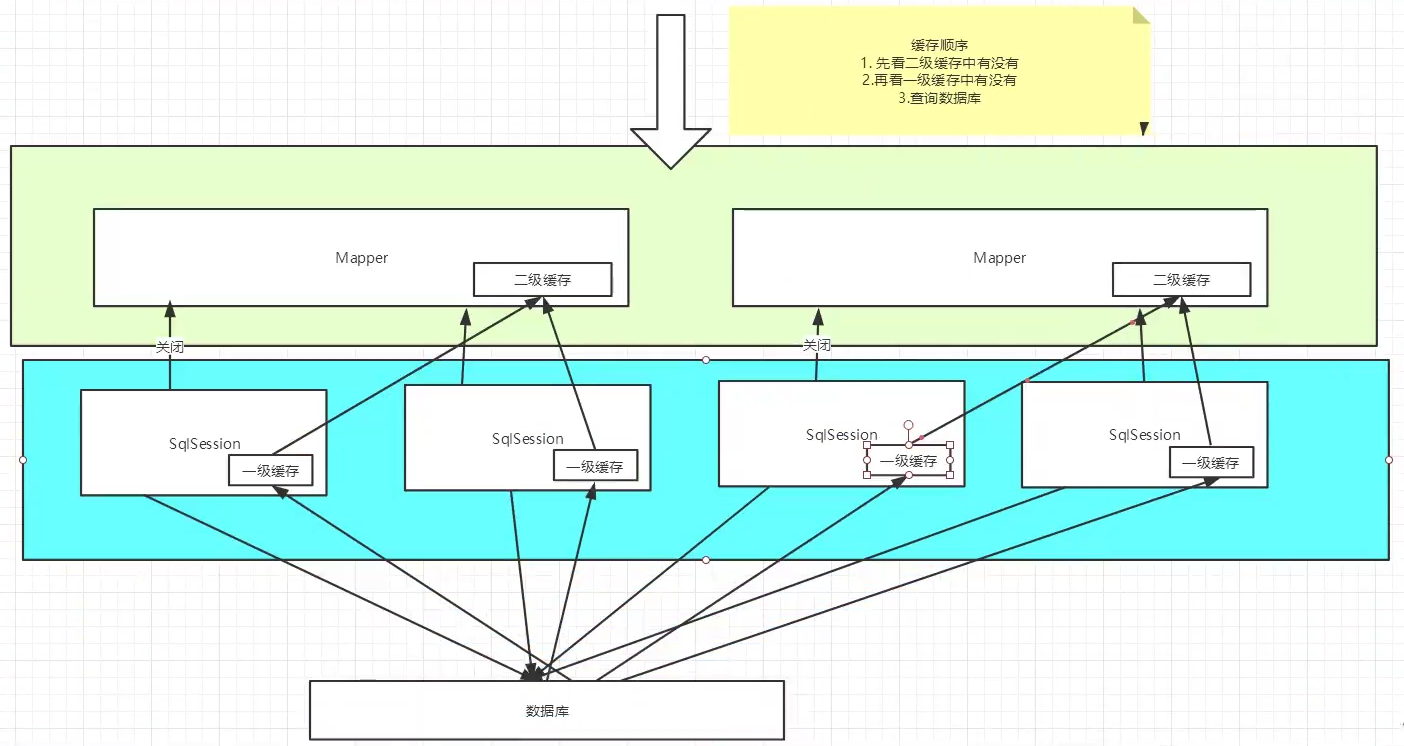
Mybatis中默认定义了两级缓存:一级缓存 和 二级缓存
默认情况下,只启用了本地的会话缓存(即一级缓存,sqlsession级别的缓存,也称为会话缓存)
二级缓存需要手动开启和配置,他是基于namespace级别的缓存
为了提高扩展性,Mybatis定义了缓存接口Cache,我们可以通过Cache接口来自定义二级缓存
一级缓存
一级缓存默认开启,我们同时查询两次
@Test
public void likeBlog(){
SqlSession sqlsession = MybatisUtil.getSqlsession();
BlogMapper mapper = sqlsession.getMapper(BlogMapper.class);
Map<String, String> map = new HashMap<>();
map.put("title","spring");
map.put("author","c");
List<Blog> blogs = mapper.likeBlog(map);
blogs.forEach(System.out::println);
System.out.println("===========================");
//在查询一次
List<Blog> blogs2 = mapper.likeBlog(map);
blogs2.forEach(System.out::println);
sqlsession.close();
}
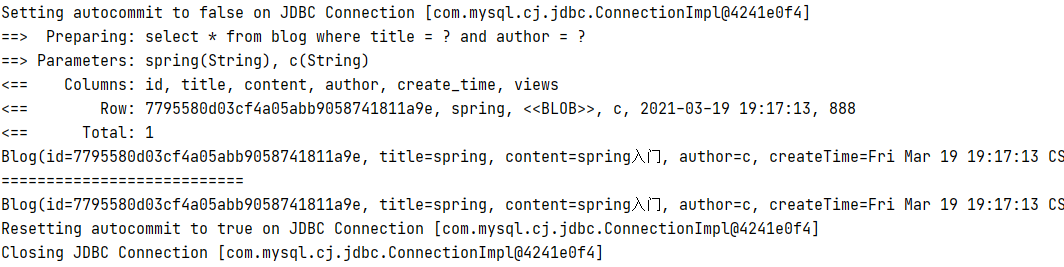
根据结果可以看出,sql语句只执行了一次。
缓存条件与实效
映射语句文件中的所有 select 语句的结果将会被缓存。
映射语句文件中的所有 insert、update 和 delete 语句会刷新缓存。
缓存会使用最近最少使用算法(LRU, Least Recently Used)算法来清除不需要的缓存。
缓存不会定时进行刷新(也就是说,没有刷新间隔)。
缓存会保存列表或对象(无论查询方法返回哪种)的 1024 个引用。
缓存会被视为读/写缓存,这意味着获取到的对象并不是共享的,可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
手动清理缓存
//调用sqlsession.clearCache()方法
sqlsession.clearCache();
小结:一级缓存默认开启,只在一次sqlsession中有效也就是拿到链接到关闭这段期间。 一级缓存就是于一个map
二级缓存
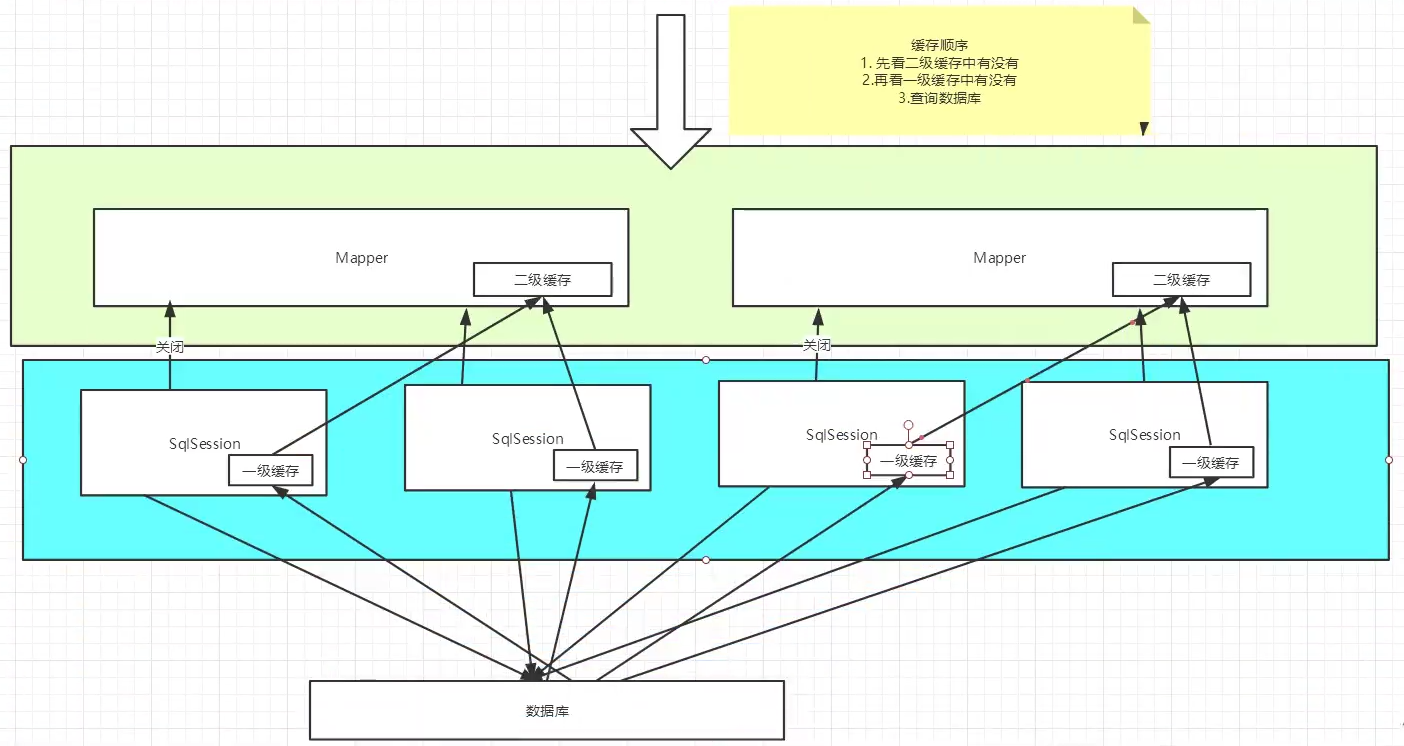
二级缓存也叫全局缓存,一级缓存作用域太低,所以诞生了二级缓存
基于namespace级别的缓存,一个命名空间,对应一个二级缓存
工作机制
一个会话查询一条数据,这个会话就会被放在当前会话的一级缓存中
如果当前会话关闭了,这个会话对应的一级缓存就没了;但是我们想要的是,会话关闭了,一级缓存中的数据被保存到二级缓存中去
新的会话查询信息,就可以从二级会话中回去内容
不同的mapper查出来的数据会放在自己对应的缓存(map)中
要启用全局的二级缓存,只需要在你的 SQL 映射文件中添加一行:
<cache/>
缓存只作用于 cache 标签所在的映射文件中的语句。如果你混合使用 Java API 和 XML 映射文件,在共用接口中的语句将不会被默认缓存。你需要使用 @CacheNamespaceRef 注解指定缓存作用域。
这些属性可以通过 cache 元素的属性来修改。比如:
<cache
<!-- 创建了一个 FIFO 缓存 -->
eviction="FIFO"
<!-- 每隔 60 秒刷新 -->
flushInterval="60000"
<!-- 最多可以存储结果对象或列表的 512 个引用 -->
size="512"
<!-- 返回的对象被认为是只读的 -->
readOnly="true"/>
缓存策略:
LRU – 最近最少使用:移除最长时间不被使用的对象
FIFO – 先进先出:按对象进入缓存的顺序来移除它们
SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象
WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象
开启步骤
直接在mapper.xml中使用是没有用的
我们要现在配置文件中开启缓存
<settings>
<!-- 显示的开启二级缓存 -->
<setting name="cacheEnabled" value="true"/>
</settings>
在在当前mapper.xml中使用二级缓存
<cache/>
也可以自定义参数
<!-- 启用二级缓存 -->
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
实体类还需要实现序列化接口
public class Blog implements Serializable
小结:
只要开启了二级缓存,在同一个mapper下就有效
所有数据都会放在一级缓存中
只有当会话提交,或者关闭的时候,才会提交到二级缓存
缓存原理
使用自定义缓存
除了上述自定义缓存的方式,你也可以通过实现你自己的缓存,或为其他第三方缓存方案创建适配器,来完全覆盖缓存行为。
自行实现或者使用第三方jar
考虑redis做缓存
以后再说---------------------------------------------